node第一步!
node在我们前端运用中频繁被提及,现在让我们来了解node是什么!
简介
Node.js是一个事件驱动I/O服务端JavaScript环境,基于Google的V8引擎,V8引擎执行Javascript的速度非常快,性能非常好。
作为异步驱动的 JavaScript 运行时,Node 被设计成可升级的网络应用。
Node 的用户不必担心死锁过程, 因为没有锁。Node 中几乎没有函数直接执行 I/O 操作,因此进程从不阻塞。由于没有任何阻塞,可伸缩系统在 Node 中开发是非常合理的。
模块化
模块化:一个.js文件就称为一个模块,模块的名字就是文件名(去掉.js后缀)
模块加载机制被称为CommonJS规范:向外暴露变量可以用module.exports = variable;,引用其他模块暴露的变量,用var ref = require(‘module_name’);,require函数是Node提供的,请求地址会依次在内置模块、全局模块和当前模块下查找。
module.exports实现:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19// 准备module对象:
var module = {
id: 'hello',
exports: {}
};
var load = function (exports, module) {
// 读取的hello.js代码:
function greet(name) {
console.log('Hello, ' + name + '!');
}
module.exports = greet;
// hello.js代码结束
return module.exports;
};
var exported = load(module.exports, module);
// 保存module:
save(module, exported);
node为每个模块先准备一个module对象,通过把参数module传递给load()函数,hello.js就顺利地把一个变量传递给了Node执行环境,Node会把module变量保存到某个地方。
最后一行由于Node保存了所有导入的module,当我们用require()获取module时,Node找到对应的module,把这个module的exports变量返回,这样,另一个模块就顺利拿到了模块的输出
Node中exports和module.exports的区别?
module.exports 初始值为一个空对象 {}, exports 是指向的 module.exports 的引用, require() 返回的是 module.exports 而不是 exports
所以当我们给exports赋值引用变量时,断开了跟module.exports的链接,指向了新的对象。
如果我们要输出的是一个函数或数组,那么,只能给module.exports赋值:1
module.exports = function () { return 'foo'; };
给exports赋值是无效的,因为赋值后,module.exports仍然是空对象{}。
如何寻址
全局变量
全局对象global和进程对象process(process是global的一个属性)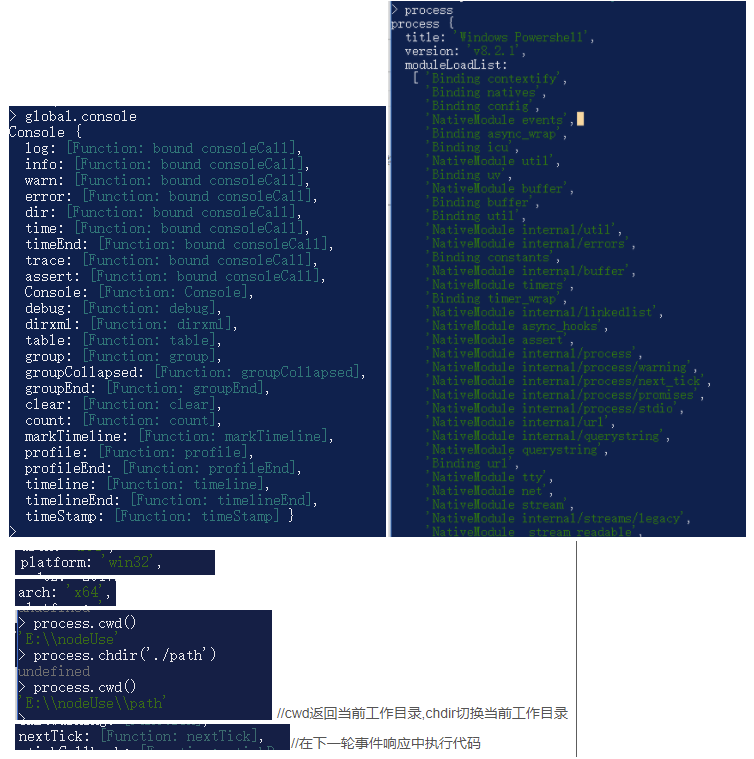
Node.js不断执行响应事件的JavaScript函数,直到没有任何响应事件的函数可以执行时,Node.js就退出了。如果我们想要在下一次事件响应中执行代码,可以调用process.nextTick()。
node进程本身的事件由process对象来处理,如果我们响应exit事件,就可以在程序即将退出时执行某个回调函数1
2
3
4// 程序即将退出时的回调函数:
process.on('exit', function (code) {
console.log('about to exit with code: ' + code);
});
基本模块
fs / stream /url /path /http /crypto
fs
| 类型 | 读文件 | 写文件 | 获取文件大小、创建时间信息 | 读取文件流 | 写入文件流 |
|---|---|---|---|---|---|
| 异步 | fs.readFile() | fs.writeFile() | fs.stat() | ||
| 同步 | fs.readFileSync() | fs.writeFileSync() | fs.statSync() | ||
| 事件驱动 | fs.createReadStream() | fs.createWriteStream() |
1 | ; |
文件流:
流的特点是数据是有序的,而且必须依次读取,或者依次写入,不能像Array那样随机定位。
在Node.js中,流也是一个对象,我们只需要响应流的事件就可以了:data事件表示流的数据已经可以读取了,end事件表示这个流已经到末尾了,没有数据可以读取了,error事件表示出错了。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28var rs = fs.createReadStream('rr2.txt', 'utf-8');
rs.on('data', function (chunk) {
console.log('DATA:')
console.log(chunk);
});
rs.on('end', function () {
console.log('END');
});
rs.on('error', function (err) {
console.log('ERROR: ' + err);
});
// var ws1 = fs.createWriteStream('rr3.txt', 'utf-8');
// ws1.write('使用Stream写入文本数据...\n');
// ws1.end();
var ws2 = fs.createWriteStream('rr3.txt');
ws2.write(new Buffer('使用Stream写入二进制数据data...\n', 'utf-8'));
ws2.write(new Buffer('END.\n', 'utf-8'));
ws2.end();
var ws1 = fs.createWriteStream('rr3.txt', 'utf-8');
ws1.write('使用Stream写入文本数据...\n');
rs.pipe(ws1);
ws1.write('END.');
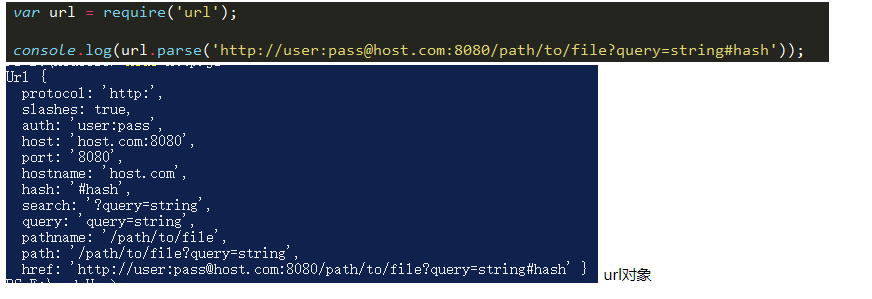
url模块:解析url
path
可以方便的构造目录
使用path模块可以正确处理操作系统相关的文件路径。在Windows系统下,返回的路径类似于C:\Users\michael\static\index.html,这样,我们就不关心怎么拼接路径了。
http
request对象,封装了HTTP请求,调用此对象属性和方法可以获取HTTP请求的信息
response对象,封装了HTTP响应,调用此对象的方法,可以把HTTP响应返回给浏览器
1 | var http = require('http'); |
一个简单的文件服务器:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64;
var path = require('path');
var workDir = path.resolve('.');
var
fs = require('fs'),
url = require('url'),
path = require('path'),
http = require('http');
// 从命令行参数获取root目录,默认是当前目录:
var root = path.resolve(process.argv[2] || '.');
// 创建服务器:
var server = http.createServer(function (request, response) {
// 获得URL的path,类似 '/css/bootstrap.css':
var pathname = url.parse(request.url).pathname;
// 获得对应的本地文件路径,类似 '/srv/www/css/bootstrap.css':
var filepath = path.join(root, pathname);
console.log(filepath);
// 获取文件状态:
fs.stat(filepath, function (err, stats) {
if (!err) {
if(stats.isFile()){
// 没有出错并且文件存在:
console.log('200 ' + request.url);
// 发送200响应:
response.writeHead(200);
// 将文件流导向response:
fs.createReadStream(filepath).pipe(response);
}
if(stats.isDirectory){
var filepath1 = path.join(filepath,'index.html');
var filepath2 = path.join(filepath,'default.html');
if(fs.existsSync(filepath1)){
// 没有出错并且文件存在:
console.log('200 ' + filepath1);
// 发送200响应:
response.writeHead(200);
// 将文件流导向response:
fs.createReadStream(filepath1).pipe(response);
}else if(fs.existsSync(filepath2)){
// 没有出错并且文件存在:
console.log('200 ' + filepath2);
// 发送200响应:
response.writeHead(200);
// 将文件流导向response:
fs.createReadStream(filepath2).pipe(response);
}
}
} else {
// 出错了或者文件不存在:
console.log('404 ' + request.url);
// 发送404响应:
response.writeHead(404);
response.end('404 Not Found');
}
});
});
server.listen(8080);
console.log('Server is running at http://127.0.0.1:8080/');
错误优先的回调函数
node的回调函数第一个参数始终是一个错误对象。1
2
3
4
5
6
7
8
9fs.readFile('rrr.txt', function (err, data) {
if (err) {
console.log(err);
} else {
console.log(data);
console.log(data.length + ' bytes');
console.log('utf-8:' + data.toString('UTF-8'));
}
});
node 的 event loop
Node.js也是单线程的Event Loop,但是它的运行机制不同于浏览器环境。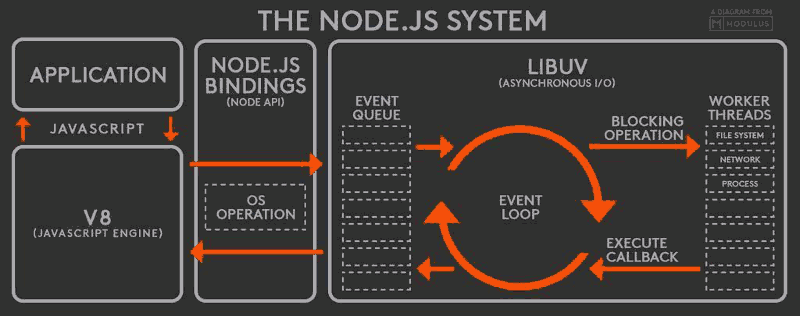
(1)V8引擎解析JavaScript脚本。
(2)解析后的代码,调用Node API。
(3)libuv库负责Node API的执行。它将不同的任务分配给不同的线程,形成一个Event Loop(事件循环),以异步的方式将任务的执行结果返回给V8引擎。
(4)V8引擎再将结果返回给用户。
除了setTimeout和setInterval这两个方法,Node.js还提供了另外两个与”任务队列”有关的方法:process.nextTick和setImmediate。
process.nextTick方法可以在当前”执行栈”的尾部—-下一次Event Loop(主线程读取”任务队列”)之前—-触发回调函数。也就是说,它指定的任务总是发生在所有异步任务之前。
setImmediate方法则是在当前”任务队列”的尾部添加事件,也就是说,它指定的任务总是在下一次Event Loop时执行,这与setTimeout(fn, 0)很像。
1 | process.nextTick(function A() { |
上面代码中,由于process.nextTick方法指定的回调函数,总是在当前”执行栈”的尾部触发,所以不仅函数A比setTimeout指定的回调函数timeout先执行,而且函数B也比timeout先执行。这说明,如果有多个process.nextTick语句(不管它们是否嵌套),将全部在当前”执行栈”执行。
1 | setImmediate(function A() { |
上面代码中,setImmediate与setTimeout(fn,0)各自添加了一个回调函数A和timeout,都是在下一次Event Loop触发。那么,哪个回调函数先执行呢?答案是不确定。运行结果可能是1–TIMEOUT FIRED–2,也可能是TIMEOUT FIRED–1–2。
1 |
|
setImmediate和setTimeout被封装在一个setImmediate里面,它的运行结果总是1–TIMEOUT FIRED–2,这时函数A一定在timeout前面触发。是因为setImmediate总是将事件注册到下一轮Event Loop,所以函数A和timeout是在同一轮Loop执行,而函数B在下一轮Loop执行。
so.个process.nextTick语句总是在当前”执行栈”一次执行完,多个setImmediate可能则需要多次loop才能执行完。事实上,这正是Node.js 10.0版添加setImmediate方法的原因,否则像下面这样的递归调用process.nextTick,将会没完没了,主线程根本不会去读取”事件队列”!1
2
3process.nextTick(function foo() {
process.nextTick(foo);
});
Node.js是单线程,如何实现多个同时的文件IO?
Node.js的fs调用V8的libuv中的uv_fs_open,绑定JS的callback到一个c的函数指针上,然后推入事件列表队列(QueueUserWorkItem),再根据操作系统,Windows下使用IOCP来完成异步IO,* NIX上使用libev来实现。说明Node.js从上层到V8是单线程,从libuv到IOCP或者libev是多线程IO读写。
so, Node采用的是单线程的处理机制(所有的I/O请求都采用非阻塞的工作方式),至少从Node.js开发者的角度是这样的。 而在底层,Node.js借助libuv来作为抽象封装层, 从而屏蔽不同操作系统的差异,Node可以借助libuv来来实现多线程。
node 优缺点
单线程:服务器无法接受新的请求,即阻塞式 I/O。
多线程:服务器每创建一个线程,每个线程大概会占用 2M 的系统内存,而且线程之间的切换也会降低服务器的处理效率。但并发量高的时候,请求仍然需要等待。成本效率低,且要考虑死锁,数据不一致等问题。
事件驱动I/O:所有请求以及同时传入的回调函数均发送至同一线程,该线程通常叫做 Event loop 线程,该线程负责在 I/O 执行完毕后,将结果返回给回调函数。 I/O 操作本身并不在该线程内执行,所以不会阻塞后续请求。但是维护事件队列也需要成本,再由于NodeJS是单线程,事件队列越长,得到响应的时间就越长,并发量上去还是会力不从心。
优点:
- 高并发(最重要的优点)
- 适合I/O密集型应用
缺点:
- 不适合CPU密集型应用;CPU密集型应用给Node带来的挑战主要是:由于JavaScript单线程的原因,如果有长时间运行的计算(比如大循环),将会导致CPU时间片不能释放,使得后续I/O无法发起;
解决方法:分解大型运算任务为多个小任务,使得运算能够适时释放,不阻塞I/O调用的发起; - 只支持单核CPU,不能充分利用CPU
- 可靠性低,一旦代码某个环节崩溃,整个系统都崩溃(单进程,单线程)
解决方案:(1)Ngix反向代理,负载均衡,开多个进程,绑定多个端口;(2)开多个进程监听同一个端口,使用cluster模块; - 开源组件库质量参差不齐,更新快,向下不兼容
- Debug不方便,错误没有stack trace
多核处理器模块cluster
nodejs是一个单进程单线程的服务器引擎,不管有多么的强大硬件,只能利用到单个CPU进行计算。所以,有人开发了第三方的cluster,让node可以利用多核CPU实现并行。在V0.6.0版本,Nodejs内置了cluster的特性。
cluster模块,可以帮助我们简化多进程并行化程序的开发难度,轻松构建一个用于负载均衡的集群。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32var cluster = require('cluster');
var http = require('http');
var numCPUs = require('os').cpus().length;
if (cluster.isMaster) {
console.log("master start...");
// Fork workers.
for (var i = 0; i < numCPUs; i++) {
cluster.fork();
}
cluster.on('listening',function(worker,address){
console.log('listening: worker ' + worker.process.pid +', Address: '+address.address+":"+address.port);
});
cluster.on('exit', function(worker, code, signal) {
console.log('worker ' + worker.process.pid + ' died');
});
} else {
http.createServer(function(req, res) {
res.writeHead(200);
res.end("hello world\n");
}).listen(0);
}
//
master start...
listening: worker 2368, Address: 0.0.0.0:57132
listening: worker 1880, Address: 0.0.0.0:57132
listening: worker 1384, Address: 0.0.0.0:57132
listening: worker 1652, Address: 0.0.0.0:57132
//master是总控节点,worker是运行节点。然后根据CPU的数量,启动worker。
原理:
每个worker进程通过使用child_process.fork()函数,基于IPC(Inter-Process Communication,进程间通信),实现与master进程间通信。
当worker使用server.listen()函数时 ,将参数序列传递给master进程。如果master进程已经匹配workers,会将传递句柄给工人。如果master没有匹配好worker,那么会创建一个worker,再传递并句柄传递给worker。
在边界条件,有3个有趣的行为:
注:下面server.listen(),是对底层“http.Server–>net.Server”类的调用。
- server.listen({fd: 7}):在master和worker通信过程,通过传递文件,master会监听“文件描述为7”,而不是传递“文件描述为7”的引用。
- server.listen(handle):master和worker通信过程,通过handle函数进行通信,而不用进程联系
- server.listen(0):在master和worker通信过程,集群中的worker会打开一个随机端口共用,通过socket通信,像上例中的57132
当多个进程都在 accept() 同样的资源的时候,操作系统的负载均衡非常高效。Node.js没有路由逻辑,worker之间没有共享状态。所以,程序要设计得简单一些,比如基于内存的session。
因为workers都是独力运行的,根据程序的需要,它们可以被独立删除或者重启,worker并不相互影响。只要还有workers存活,则master将继续接收连接。Node不会自动维护workers的数目。我们可以建立自己的连接池。
进行负载均衡:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22var cluster = require('cluster');
var http = require('http');
var numCPUs = require('os').cpus().length;
if (cluster.isMaster) {
console.log('[master] ' + "start master...");
for (var i = 0; i < numCPUs; i++) {
cluster.fork();
}
cluster.on('listening', function (worker, address) {
console.log('[master] ' + 'listening: worker' + worker.id + ',pid:' + worker.process.pid + ', Address:' + address.address + ":" + address.port);
});
} else if (cluster.isWorker) {
console.log('[worker] ' + "start worker ..." + cluster.worker.id);
http.createServer(function (req, res) {
console.log('worker'+cluster.worker.id);
res.end('worker'+cluster.worker.id+',PID:'+process.pid);
}).listen(3000);
}
